 Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

Dev Log #72 (Patreon)
Content
I released v0.26.0 and nobody has reported any catastrophic show stopping bugs yet so I guess it's a success, or not many people have tried it yet. I also assume that the package is properly notarized and macOS user are able to open now it with no problems.
It feels important to me to be able to keep uploading new alpha builds since I have nothing else to offer for Patreon rewards except for these boring blog posts. This sometimes leads to an unnecessary amount of stress especially when I say something like "the build will probably be ready in a couple of weeks" and then it ends up taking five times as long.
Another issue with building up these big release milestones in my head is at a certain point I am just trying to get everything working so I can finally upload it to Patreon, and I'll start hacking in fixes for things instead of coding things properly. So there is a little bit of string and glue holding v0.26.0 together and i have a lot of "fix this properly after v0.26.0 is released" notes to go through now.
There are some known bugs which will probably stay on the backburner for a while because I really want to continue fleshing out the main functionality of Blockhead. Things like "it's not possible to bounce send/receive block" will probably remain a known bug for a while because it requires a bit of engineering work to fix and I don't think anybody uses send/receive blocks anyway.
I hope feature updates will start coming a lot quicker now since nothing I have planned is as big and complicated as macros were. Probably the next main feature that I will work on is the ability to save and load blocks to and from disk. Though I also want to throw away most of the right-hand panel stuff and replace the sample list and block list with something much better, so I might roll the block saving/loading into that.
The problem is I am still not sure exactly how that interface is going to look and I probably won't really know until I get around to figuring out how the MIDI/instrument system is going to work, so maybe I should start thinking about that first.
What I've been doing
Replaced boost::signals2 with my own signal/slot connection library
Pretty much immediately after releasing v0.26.0 I started to work on this. I had been wanting to do it for ages but I was putting it off while trying to get v0.26.0 done.
Like all great codebases Blockhead is largely implemented as a C++ object oriented spaghetti hell scape and as such it uses signals and slots to allow objects to communicate with one another.
Signals and slots are basically this kind of thing:
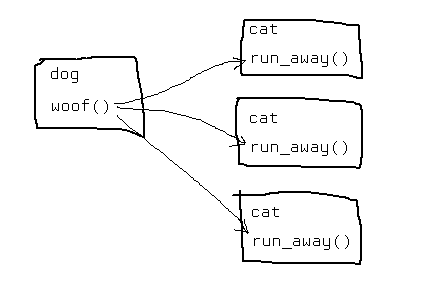
There's a dog and three cats. When the dog woofs the cats are supposed to run away. So what you can do is have a woof() method that calls each cat's run_away() method. The dog would have to keep track of all the cats though so it can go through and update each one.
Instead of doing that you can have a thing called a "signal", in this case a "woofed" signal. And other objects in the system can "connect" to it.

In this case each cat has an "on_dog_woofed()" method which is connected to the dog's "woofed" signal. A method connected to a signal is sometimes called a "slot".
The woofed signal itself keeps track of all the slots that have been connected to it. Every time we want the dog to woof we just trigger the "woofed" signal and each slot gets called automatically by the signal/slot system.

There are all kinds of problems with this approach to architecting things but the benefit is that it lets you build up complicated interactions between things in a system pretty quickly with a minimal amount of boilerplate.
To write this stuff easily you need some kind of library which encapsulates all that connection and signalling logic. For a long time I have been relying on a the boost::signals2 library for this. Unfortunately the library proved to be a performance bottleneck during profiling, especially when dragging blocks around when there are many nested macros in a workspace.
boost::signals2 is thread-safe by default so it does a bunch of mutex locking internally which I thought might have been the main issue. Blockhead only ever uses signals and slots in one thread so it doesn't need them to be thread-safe, and boost::signals2 does have a way to disable thread-safety by supplying a dummy mutex. Unfortunately I tried that and the difference was very marginal.
So I ended up writing my own signal/slot library which is only a slightly more complicated problem than you might imagine for what should be, on the face of it, a vector of callbacks. I then wrote another library on top of that to replace the property system that I was also relying on boost::signals2 for. I then went through the entire Blockhead codebase and switched everything over to use these new libraries, which took several days even with a lot of find+replace work. Everything seems to be working perfectly so far and the performance is much better.
What I'm doing now
Rewriting everything to do with drag+drop, block stamping and block resizing.
This stuff was one of the first things I ever worked on in Blockhead. It used to be entirely written in GDScript and it was dreadful. I then threw it all away and rewrote it all in C++ and it was still dreadful. I then threw all that C++ code away and rewrote it again and it was slightly less dreadful. That's where we are now.
The code is still very hard to follow and every time it has to change is a massive pain. I end up hacking things in to get them working so the system has bloated out over time.
With macros there is this new thing where you can drag a selection over the "create macro" widget at the bottom of the workspace, release the mouse button and then it has to sort of shut down the drag/drop system and transition into the new macro stamping system.
It all works fine but the code is just a mess so I've been really wanting to have another run at improving things.
When I rewrote the audio engine a couple months back it was pretty satisfying because the entire thing was rewritten in a value-oriented design which tends to result in simpler code than object-oriented. Value-oriented design is sort of a trendy topic in the c++ world over the past few years and I am not necessarily 100% on board with it but it felt like the right solution to the technical issue I was having at the time.
It was quite easy to make this transition because the audio engine was already very well separated from everything else and I already had a pretty clean interface set up between audio and GUI. I already sort of had an audio "model" which contained the bare minimum object data required to render the various blocks, lanes, tracks and workspaces, but it was all scattered around inside different object-oriented data structures. Whereas now the entire model is more or less defined in one place.
The audio-side of the codebase was never exactly terrible but I was quite impressed with how much cleaner the new code was so I started looking for other areas of the codebase that I could try applying the same treatment to.
I ended up rewriting blockhead's "snapshot" system. This system sort of sits halfway between audio and GUI and was also already quite well encapsulated. Basically it is the system that handles bouncing and baking. Any time a bounce or a bake occurs Blockhead creates a "snapshot" which is essentially a copy of all the ingredients required to produce the bounced/baked result, which is rendered in another thread.
Again this is now implemented as a nice clean value-oriented data model and I was similarly impressed with how much clearer I was able to make the code.
So now I have this long running problem of the drag/drop/stamping system which I want to deal with, and this magic new way of structuring things which seems to make code cleaner.
The drag/drop system is already reasonably well separated from everything else, despite interacting quite heavily with the other subsystems, and despite being a big mess. The actual logic of how blocks move/drag around and where they end up on the workspace is quite well encapsulated from the rest of Blockhead, but then there is all this other crap mixed in there which deals with actually reaching into the block objects and updating them.
In the case of the audio system and the snapshot system, those systems aren't actually interacting with the same block objects as the user is when they click around doing things in the GUI. Instead, a copy of the required data is passed into those systems and stored in their respective models. The data can be organized in a way that is best suited for dealing with it, rather than having it all scattered around between different objects.
With the drag/drop system things are a bit different, because it has to interact directly with other objects in the larger system and it's not feasible for me to convert the entirety of Blockhead's codebase over to a value-oriented design. Things like blocks, lanes, tracks and workspaces are going to have to remain in the object-oriented world.
I had a think about it and I'm pretty happy with what I've managed to set up so far.
The new drag/drop system has its own data model. When a drag/drop/stamp/resize/whatever operation is started (usually when the user presses down on the mouse button), all the block data involved in the operation is passed into the model.
In the case of a drag operation this would include the data of all the blocks in the current selection, and all the blocks still remaining on the workspace which can be collided with. But only the data that we care about for drag/drop operations is stored in the model (position, size, what lane they started on, etc.)
Manipulating the model involves dispatching actions via a controller. Every time the model changes, a diffing algorithm is run to compare the old version of the model to the new one to find out what changed (this is more efficient than it sounds thanks to the persistent data structures library that I use.)
Different changes to the model produce different "effects" depending on what kind of operation the user is performing (be it a drag, a resize, a block stamp or whatever.) The "effects" are basically just functions that get run, and that's where we reach back out into the object-oriented world to finally update the block objects.
The drag/drop model is a stripped-down understanding of the current workspace situation (where all the tracks, lanes and blocks are), which blocks are being manipulated, and also a subset of the user input data (mouse clicks and movement). But I also break the functional programmers' hearts by passing in a pointer to each block so that I can actually update them, so it's not a "pure" value-oriented design.
I spent a couple of days on this now and it has involved writing a LOT of boilerplate code. I just finished re-implementing very basic block dragging and the system seems to be working perfectly so far. There is a lot of things to get through - off the top of my head: lane insertions, sample/block/copy/clone stamping, resizing and sample overriding, and make it all work with the undo/redo system.
As Blockhead grows there are only going to be more and more ways to create/manipulate blocks and move them around on the workspace so I think if I put the work in and finally clean up this part of the codebase it will be totally worth it.